Python Hash Tables Under the Hood

Table of Contents
Are you a Python developer eager to learn more about the internals of the language, and to better understand how Python hash tables and data structures work? Or maybe you are experienced in other programming languages and want to understand how and where hash tables are implemented in Python? You’ve come to the right place!
By the end of this article, you will have an understanding of:
- What a hash table is
- How and where hash tables are implemented in Python
- How the hash function works
- What’s happening under the hood in dictionaries
- The pros and cons of hash tables in Python
- How are Python dictionaries so fast
- How to hash your custom classes
This tutorial is aimed at intermediate and proficient Python developers. It assumes basic understanding of Python dictionaries and sets.
Let’s dive into looking at Python hash tables!
Learning the Basics of Hash Tables
Before diving into the Python implementation details, you first need to understand what hash tables are and how to use them.
What Is a Hash Table
Have you ever thought about how a Python dictionary is stored in memory? The memory in our computers can be thought of as a simple array with numeric indexes:
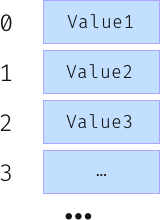
A hash table is a structure that is designed to store a list of key-value pairs, without compromising on speed and efficiency of manipulating and searching the structure.
A hash table uses a hash function to compute an index, into an array of slots, from which the desired value can be found.
How Does a Hash Function Work
A hash function, in its simplest form, is a function that computes the index of the key-value pair — so you can quickly insert, search and remove elements in your memory array.
You should start off with a simple example: A dictionary-like object, containing 3 products and their inventory count.
{"avocados": 10, "oranges": 4, "apples": 2}
As for the hash function, you would need a method to turn the string keys into numeric values so you can quickly look them up in the memory.
Try it yourself
So you’ve decided to calculate the length of the string values, awesome! Don’t forget that the numeric values must be within 0 to 3 for them to fit inside the 3 elements array. You can use the modulo operator on the lengths for that:
length of the key % table_size (3)
For example, avocados has 8 letters, therefore it would be placed in the 2nd index. This is the final array:
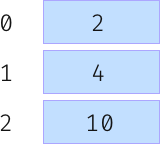
Hurrah! You’ve just built your first hash table! Hold on for a second there. What happens when two keys has the same length? You won’t be able to insert both at the same index. This is called a hash collision.
How to Handle Collisions
Hash collisions are practically unavoidable when hashing a random subset of a large set of possible keys. There are multiple strategies for collision handling - All of which require that the keys be stored in the table, together with the associated values. Two of the most common ones are Open Addressing and Separate Chaining.
-
Open Addressing: When a hash collision occurs, this algorithm proceeds in some probe sequence until an unoccupied slot is found. This startegy consists of storing all records in a single array. For example, a simple implementation of this strategy would be to proceed one element further every time that the calculated index is already occupied, until an unoccupied spot is found. This implementation is called linear probing.
Consider the following example of a simple hash table mapping names to phone numbers using your hash function from earlier:
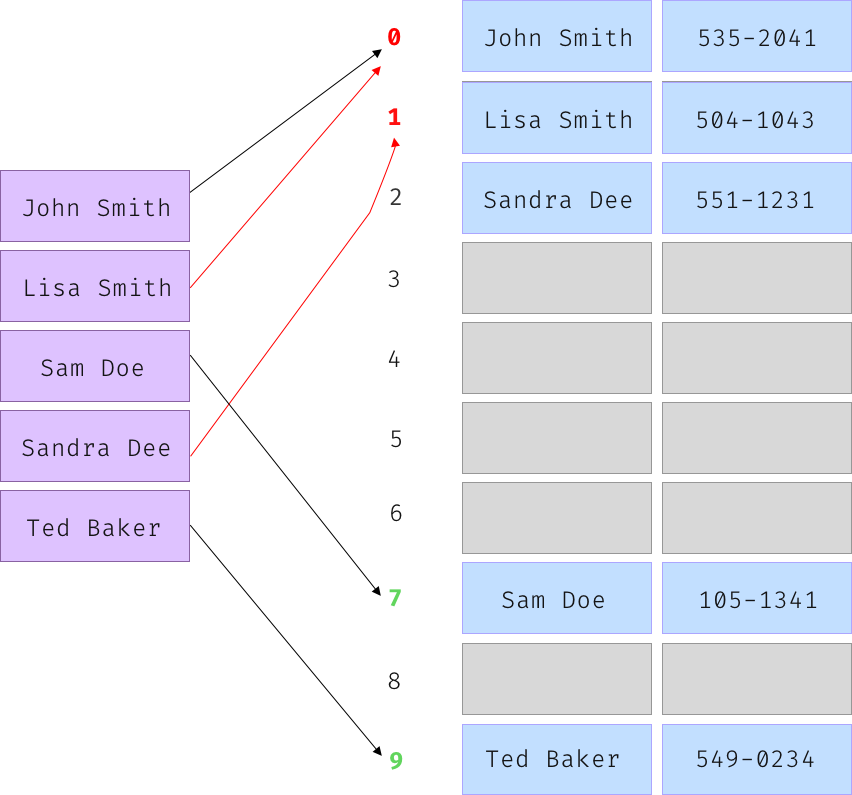
John and Lisa collide since they both hash to the index 0. Lisa was inserted after John, so it got inserted into one index further - 1. Note that Sandra Dee has a unique hash, but nevertheless collided with Lisa Smith, that had previously collided with John Smith.
- Separate Chaining: As opposed to open addressing, this strategy consists of storing multiple arrays. Each record contains a separate array which holds all of the elements with the same calculated index. The following is the sample table from earlier, using the separate chaining strategy:
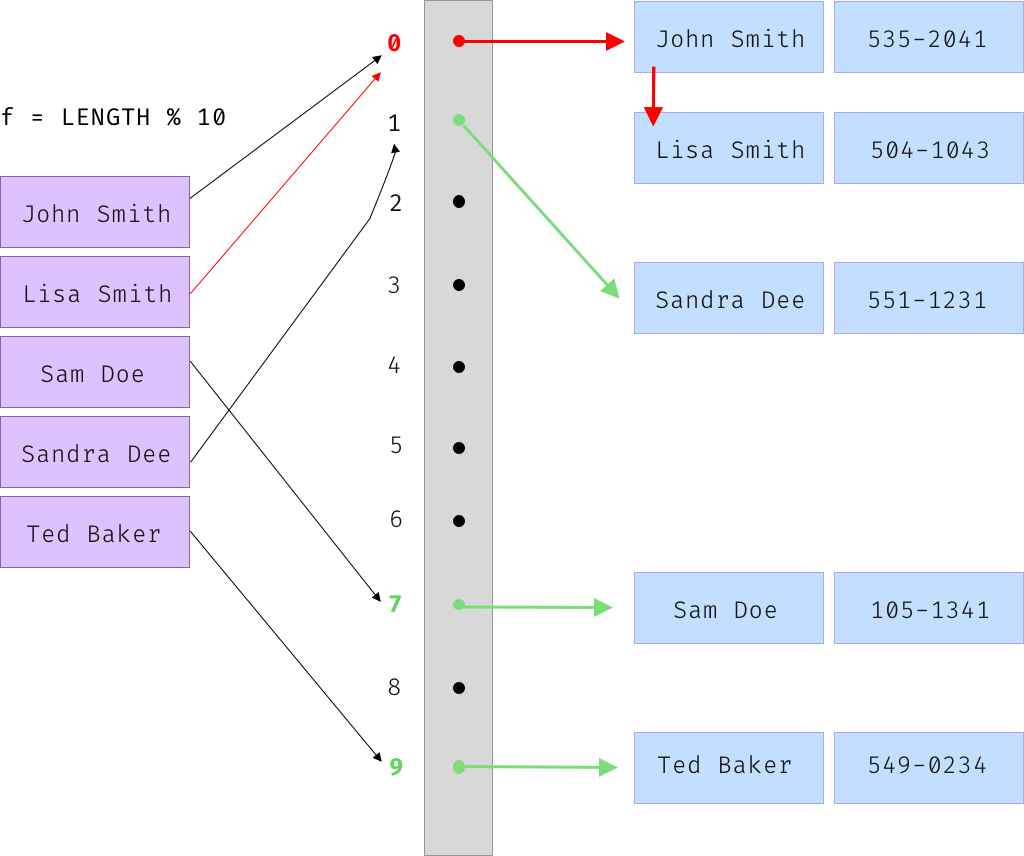
This time, Sandra Dee did not collide with Sandra since each element holds a pointer to an array of collided records.
Understanding Python Hash Tables
When you come to think about it, Python dictionary keys allow way more types than just integers. They can be strings, functions, and more. How does Python store these keys inside the memory, and know where to find their values?
You guessed it right - hash tables! Python implements hash tables under the hood, an implementation that is completely unvisible for you as a developer. Nonetheless, it could be of great use for you to understand how Python hash tables are implemented, their optimizations, and how to use them wisely.
Let’s dive into some of the internals to better understand how all of these new concepts you’ve just learned are put to practice.
Exploring Python Hash Function
Python hash function takes a hashable object and hashes into 32/64 bits (depends on the system architecture). The bits are well distributed as can be seen in the following example, showing two very similar strings - “consecutive strings”, commonly used in dictionaries, with very different hash values:
>>> "{0:b}".format(hash('hash1'))
>>> '110000010001001001011000101001010110101110010010000001101111'
>>> "{0:b}".format(hash('hash'))
>>> '101110001101101111011001100001110000000110011011000110110000'
This distribution lowers the odds of a hash collision, which in turn makes the dictionary much faster. Furthermore, you should know that a hash value is only constant for the current instance of the process. You might have stumbled upon different hashes of the same object and wondered why it happened. The main reason for this phenomenon is security related: Hash tables are vulnerable to hash collision DoS attacks when using constant hash values. Python 3.6 introduced an implementation of SipHash to prevent these attacks. You can read more about it on PEP 456. The following demonstrates different hashes on two different runs:
>>> hash("hash")
832529968546820528
>>> # different run
>>> hash("hash")
8049792375956551724
Handling Collisions in Python
Python uses open addressing to resolve hash coliisions. Python source code suggets that open addressing is preferred over chaining since the link overhead for chaining would be substantial. Earlier, you’ve seen an example of linear probing. Python uses random probing, as can be seen in the source code, or in this very simplified Python code:
perturb = hash
perturb >>= 5
new_hash = (current_index*5 + 1 + perturb)
Much like linear probing, the first part of this algorithm proceeds in a fixed manner (current_index*5+1). Python core developers found it to be good in common cases where hash keys are consecutive. The other part of this algorithm is what makes it random - The perturb variable depends on the actual bits of the hash, and as you’ve seen before - They are well distributed and not often the same even for similar keys.
Deleting Elements Using Dummy Values
In a perfect world with no collisions, deleting elements would be simple: just remove the element at the desired index so it can be refilled with other values. Unfortunately, we do not live in a perfect world, and collisions happen frequently. Remember the open addressing example from before?
Now assume you wanted to delete John Smith from the table. Seems trivial, right? Hash John Smith and delete the element located at the calculated index. Now, you might have already noticed the problem in this approach. After deleting John, Sandra is unreachable! Hashing Sandra will get us to an empty slot. For this exact reason, Python implements dummy values - Instead of completely erasing John’s element, it would place a fixed dummy value there. When the algorithm faces a dummy value, it knows that there was a value there but it got deleted. It then keeps probing forward.
Implementing Everything With Python
Now that you know what hash tables are, how the Python hash function works and how Python handles collisions, it’s time to see these things in action by exploring the implementation of a dictionary and the lookup method. The lookup method is used in all operations: search, insertion and deletion.
First thing you need to know is that Python initializes a dict with an 8 element array. Experiments showed that this size suffices for most common dicts, usually created to pass keyword arguments. Each element in the array holds a structure that contains the key, value and the hash. The hash is stored in order to not recompute it with each increase in the size of the dictionary (further explained in Exploring Python Hash Tables Optimizations: Dictionary Resize).
Note
On to the lookup method. Here’s a simplified Python version, followed by an explanation:
1 DUMMY = -2
2 def lookup(key: Any, hash_: int) -> Tuple[int, Any]:
3 mask = len(table) - 1
4 freeslot = None
5 for index in generate_probes(hash_, mask):
6 elem = table[index]
7 if elem is None:
8 return (index, None) if freeslot is None else (freeslot, DUMMY)
9 elif elem == DUMMY:
10 if freeslot is None:
11 freeslot = index
12 elif elem.key is key or (elem.hash == hash_ and elem.key == key):
13 return (index, elem)
-
Line 5 calculates the index with the
generate_probesmethod shown in the next code block below. -
Line 8 checks if the found index is empty, and returns a tuple
(index, None)for the caller to handle (search operation would raise a KeyError, insertion would insert), unless a dummy was found earlier, in which case return(index, DUMMY)for the caller to handle (search operation would raise KeyError but it had to continue searching after the dummy). -
Line 9 checks if the found index contains a dummy value, if so it keeps searching and saving that index for line 8.
-
Line 12 compares the identities of the keys. If they are the same object, the index is returned.
If not, it compares the key value and the hash. As it is known, equal objects should have equal hashes, which means that objects with different hashes are not equal. If both are equal, the index is returned.
-
If the desired element hasn’t been found yet (remember that the slot wasn’t empty/dummy), this is a hash collision situation - In which the script goes back to the
generate_probesmethod to compute the random new hash and then go back to the first step.
1 def generate_probes(hash_: int, mask: int) -> Iterable[int]:
2 index = hash_ & mask
3 yield index
4 perturb = hash_
5 while True:
6 new_hash = index * 5 + 1 + perturb
7 yield new_hash & mask
8 perturb >>= 5
- Line 3 masks the hash bits with the size of the table minus one - For example, in a table with the size of 8, the last 3 bits would be taken (111 in binary equals 7 in decimal, so 3 bits can represent 0-7). The following demonstration shows a hash example with its last 3 bits taken for indexing:
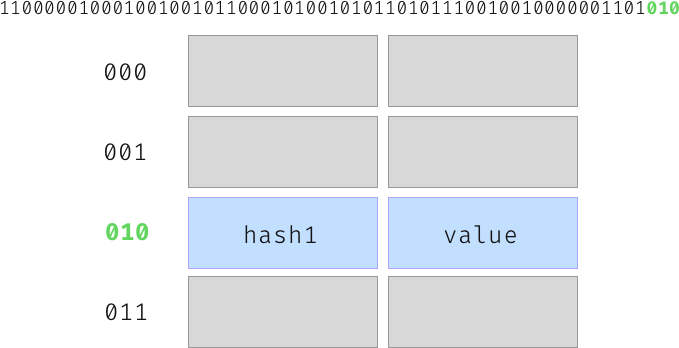
- Line 7: Remember that the algorithm goes back to the
generate_probesmethod if the desired wasn’t found? This is the line that it goes back to. It computes the new hash using a random probe and yields control back to thelookupmethod.
If you were to write the search operation, it would have looked along the lines of the following:
1 def search(key: Any) -> Any: # usually implemented as __getitem__
2 hashvalue = hash(key)
3 index, elem = lookup(key, hashvalue)
4 if elem is None or elem == DUMMY:
5 raise KeyError(key)
6 return table[index]
As I’ve mentioned before, the DUMMY and None handling is done within the caller - while this specific method raises a KeyError, other operations could have still used that index as you will soon see.
Comprehension Check
Understanding Python Sets
Along with dictionaries, Python hash tables also serve as the underlying structure for sets. Both implementations are quite similar as can be seen in the source code, with the exception that sets do not store a value for each key, meaning the optimizations of Python, which are shown later in this article, are not applicable for them. The usage of hash tables for sets make the lookup operation, which is used frequently in sets in order to keep them without duplicates, quite fast (as you should know by now - It always depends on the collisions).
Exploring Python Hash Tables Optimizations
The methods above are not entirely identical to Python’s. I didn’t want to overcomplicate things, so I’ve left out some details that make the Python dictionary blazing fast. The following section will guide you through building a custom dictionary, implementing the optimizations of Python hash tables.
Your first step would be to create a Dictionary class:
1 class Dictionary:
2
3 def __init__(self, *args, **kwargs):
4 """Dict initializiation"""
5
6 @staticmethod
7 def _generate_probes(hash_: int, mask: int) -> Iterable[int]:
8 index = hash_ & mask
9 yield index
10 perturb = hash_
11 while True:
12 new_hash = index * 5 + 1 + perturb
13 yield new_hash & mask
14 perturb >>= 5
15
16 def _lookup(self, key: Any, hashvalue: int) -> Tuple[int, Any]:
17 """The lookup method"""
18
19 def __getitem__(self, key: Any) -> Any:
20 """Get value from dict"""
21
22 def __setitem__(self, key: Any, value: Any):
23 """Insert item to dict"""
24
25 def __delitem__(self, key: Any):
26 """Delete item from dict"""
27
28 def __len__(self) -> int:
29 """Dict length"""
30
31 def __iter__(self) -> Iterable:
32 """Iterate through dictionary"""
33
34 def __contains__(self, key: Any) -> bool:
35 """Check if dictionary contains a key"""
36
37 def __repr__(self) -> str:
38 """Dict representation"""
You will soon fill up these methods. Notice that generate_probes is now a static method - No reason for it to be an instance method since it does not use any instance attributes. lookup and search from before are not used since they both will change quite a bit.
Let’s dive into Python hash tables optimizations!
Compact Dictionaries
Compact dictionaries optimize the space that hash tables occupy. Before they were implemented, Python has had sparse hash tables - Each unoccupied slot took as much space as an occupied slot because it had to save space for the key, hash and value. Compact dictionaries introduced a much smaller table just for indices, and a separate table for the keys, values and hashes. This way, the indices table could be the sparse one while the bigger table is dense.
For example, before compact dictionaries, the following is how a dictionary and its corresponding memory array looked like (taken from Raymond Hettinger’s text):
d = {'timmy': 'red', 'barry': 'green', 'guido': 'blue'}
[['---', '---', '---'],
[-8522787127447073495, 'barry', 'green'],
['---', '---', '---'],
['---', '---', '---'],
['---', '---', '---'],
[-9092791511155847987, 'timmy', 'red'],
['---', '---', '---'],
[-6480567542315338377, 'guido', 'blue']]
Instead, with compact dictionaries, two different tables are built:
[None, 1, None, None, None, 0, None, 2]
[[-9092791511155847987, 'timmy', 'red'],
[-8522787127447073495, 'barry', 'green'],
[-6480567542315338377, 'guido', 'blue']]
Take Timmy for example. It gets hashed into the 5th index, which contains the number 0 in the indices table, which in turn contains the actual timmy element in the entries table.
Raymond Hettinger, the creator of compact dictionaries, said:
The memory savings are significant (from 30% to 95% compression depending on the how full the table is).
In addition to space savings, the new memory layout makes iteration faster. keys/values/items can loop directly over the dense table, using fewer memory accesses.
This piece of code inserts new elements to a dictionary, and checks the size after each insertion until it reaches 1000 elements. Here’s how Python 3.8 compact dictionary sizes compare to Python 2.7 non-compact dictionaries:
| Number of keys | 3.8 Size | 2.7 Size | Multiplier |
|---|---|---|---|
| < 6 | 232 | 280 | 1.2 |
| < 11 | 360 | 1048 | 2.9 |
| < 22 | 640 | 1048 | 1.6 |
| < 43 | 1176 | 3352 | 2.8 |
| < 86 | 2272 | 3352 | 1.5 |
| < 171 | 4696 | 12568 | 2.5 |
| < 342 | 9312 | 12568 | 1.3 |
| < 683 | 18520 | 49432 | 2.7 |
| < 1000 | 36960 | 49432 | 1.3 |
In order to implement this feature in your custom dictionary, the dictionary needs to implement two separates arrays: one for the indices and one for the actual entries. Before you do that, there are other optimizations to consider, therefore the final implementation will take place soon, in Putting it All Together.
Meanwhile, you can create the method that builds the indices array, and initialize the class with indices, filled and used variables:
1 FREE = -1
2 DUMMY = -2
3
4 class Dictionary:
5 def __init__(self, *args, **kwargs):
6 self.indices = self._make_index_array(8) # Init with an 8 elements table
7 self.used = 0 # Number of items in the dictionary
8 self.filled = 0 # Number of non-empty slots including dummy slots
9
10 @staticmethod
11 def _make_index_array(n: int) -> Union[list, array.array]:
12 if n <= 2 ** 7:
13 return array.array("b", [FREE]) * n # signed char
14 if n <= 2 ** 15:
15 return array.array("h", [FREE]) * n # signed short
16 if n <= 2 ** 31:
17 return array.array("l", [FREE]) * n # signed long
18 return [FREE] * n
-
The indices array is of a single type, therefore
DUMMYandFREEshould be of the same type. -
The
indicesarray will hold the sparse table of indices (pointing to the actual entries) -
usedandfilledvariables are used to hold the size of the dictionary with and without dummy values (respectively) -
_make_index_arrayuses the array module in order to compactly represent an array of basic values. It follows the logic of Python source code in order to determine the size of the indices.
Note
Key Sharing Dictionaries
Python 3.3 introduced key-sharing dictionaries. When dictionaries are created to fill the dict slot of an object, they are created in split form. The keys table is cached in the type, potentially allowing all attribute dictionaries of instances of one class to share keys. This behaviour happens in the __init__ method of classes, and aims to save memory space and to improve speed of object creation. Your takeaway from this should be to always strive to assign attributes in the __init_ method so your custom classes can use key-sharing dictionaries.
The following visual demonstrates three instances of the same class:
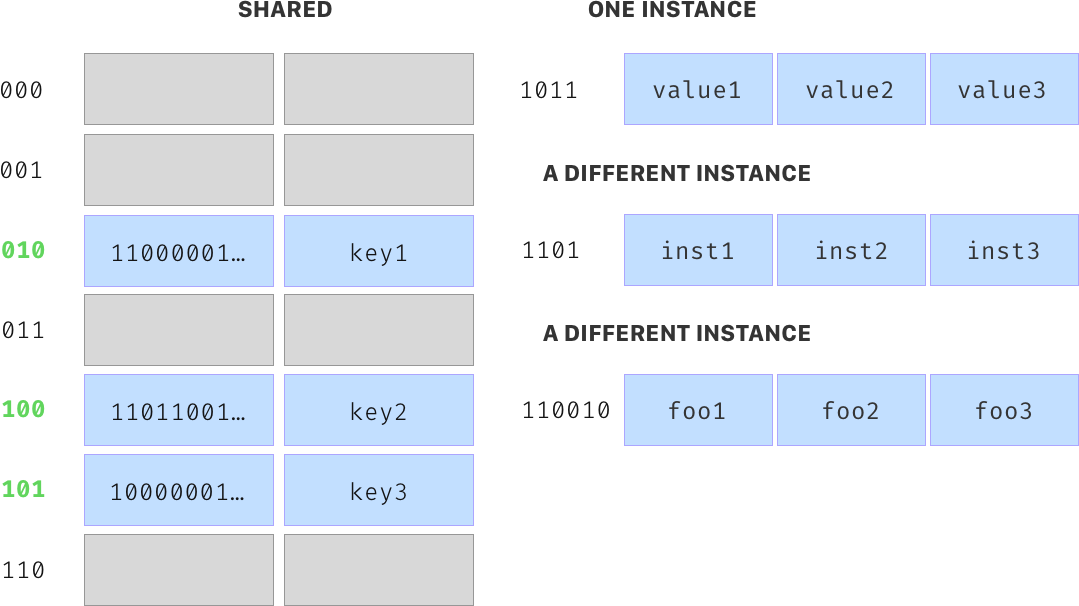
You can see that each instance only holds its values, while there is a single, shared place in memory for the keys.
Let’s implement this awesome feature in your dictionary:
1 class DictKey:
2 __slots__ = ["key", "hashvalue"] # does not need a __dict__
3
4 def __init__(self, key, hashvalue):
5 self.key = key
6 self.hashvalue = hashvalue
7
8 def __repr__(self):
9 return f"<DictKey {self.key}>"
10
11 class Dictionary:
12
13 def __init__(self, *args, **kwargs):
14 self.indices = self._make_index_array(8) # init with an 8 elements table
15 self.keys: List[DictKey] = []
16 self.values: List[Any] = []
17 self.used = 0 # number of items in the dictionary
18 self.filled = 0 # number of non-empty slots including dummy slots
19 self.update(*args, **kwargs)
20
21 def update(self, other=(), /, **kwargs):
22 self._sharing_keys = False
23 if isinstance(other, Dictionary):
24 if self.used > 0:
25 for key in other:
26 self[key] = other[key]
27 else:
28 self._sharing_keys = True
29 self.indices = copy.copy(other.indices)
30 self.keys = other.keys
31 self.values = [None] * len(other.values)
32 self.used = other.used
33 self.filled = other.filled
34 elif hasattr(other, "keys"):
35 for key in other.keys():
36 self[key] = other[key]
37 else:
38 for key, value in other:
39 self[key] = value
40 for key, value in kwargs.items():
41 self[key] = value
42
43 def _check_keys_sharing(self):
44 """if trying to change dictionary with shared keys,
45 migrate to non shared dictionary"""
46 if self._sharing_keys:
47 self.keys = copy.copy(self.keys)
-
Line 1 creates a
DictKeyclass which holds a key and its hash value -
Lines 15-16 sets two separate lists for entries: One for the keys, which may be shared with other instances, and one for the values.
-
Line 19: The dictionary is planned to be initialized with values. The
updatemethod takes care of that: No matter what type of argument received, as long as its an iterable, the dictionary will use its contents. -
Line 22 sets
_sharing_keystoFalsein order to mark whether this instance shares its keys with other instances. -
Lines 23 checks if a
Dictionaryarguments was given as argument, then it goes on to checking if the current dictionary is already filled with keys and values. If so, it copies the keys and values from the other dictionary.If the current dictionary is not filled, there’s the key sharing awesomeness! Line 28 copies the other dictionary
indicesin order to preserve functionallity.keysandvaluesmust remain in sync, sovaluesneeds to be initalized withNonevalues since you don’t want the values of the other dictionary. The other instancekeysis then only referenced byself.keys. -
If the other instance is not of type
Dictionary, line 34 checks if it has akeysattribute, like a real dictionary. If so, it copies its keys and values. -
If all else fails, line 38 treats the other instance as if it had keys and values in it and copy them.
-
Finally, line 40 copies the keys and values given in
**kwargsas well. -
_check_keys_sharingconverts the dictionary to a non-shared dictionary. It is planned to be called when a shared dictionary tries to change its values.
Dictionary Resize
Python checks for the table size everytime we add a key, and if the table is two-thirds full, it would resize the hash table. If a dictionary has 50000 keys or fewer, the new size is used_size * 4, otherwise, it is used_size * 2. Remember that Python stores the hash value along with the key and the value? This is where it comes in handy! Instead of rehashing the keys when inserting them to the new bigger table, the stored hashes are used. You might wonder - What if the key object was changed? In this case, the hash should be recalculated and the stored value will be incorrect? Such a situation is impossible, since mutable types cannot be keys of a dictionary. Here’s how you implement the resize operation:
1 class Dictionary:
2 def _resize(self, n: int):
3 n = 2 ** n.bit_length()
4 self.indices = self._make_index_array(n)
5 for entry_index, dict_key in enumerate(self.keys):
6 for i in self._generate_probes(dict_key.hashvalue, n - 1):
7 if self.indices[i] == FREE:
8 break
9 self.indices[i] = entry_index
10 self.filled = self.used
-
Line 3: Python hash table sizes are powers of 2, so we will also use powers of 2. The primary reason Python uses “round” powers of 2 is efficiency: computing
% 2**ncan be implemented using bit operations, as you’ve seen before. -
Line 4 builds a new
indicesarray with the new bigger size. -
Lines 5 - 9 loops through the keys. For every key, it generates an index. If that index is free in the new indices table, it inserts that key’s index into the indices table. Essentially, what this piece of code does is to allocate a new indices table and fill it up with the current keys. Notice no hashing is needed because the hashes are saved.
-
Line 10:
filledshould be equal tousedsince nothing was deleted yet - there should not be any dummy values.
Private Dictionary Versions
Python 3.6 added a new private version to dictionaries, incremented at each dictionary creation and at each dictionary change. The rationale is to skip dictionary lookups if the version does not change, and to use cached values instead. Your implementation can implement a version for each instance, although it won’t implement the actual caching of values.
1 class Dictionary:
2 __version = 0
3
4 def _increase_version(self):
5 self.__version = Dictionary.__version
6 Dictionary.__version += 1
7
8 def __init__(self, *args, **kwargs):
9 self._increase_version()
-
The
__versionvariable keeps a counter of the number of dictionary instances, so each instance can have a unique version. -
_increase_versionis planned to be called by operations such as__setitem__and__delitem__. It sets the current instance’s version to the latest of the class variable, and increases the class variable by one. -
Line 9 initializes the dictionary with the latest version.
Putting It All Together
Note
It’s time to use all these cool new methods and make your dictionary usable!
_lookup
1 def _lookup(self, key: Any, hashvalue: int) -> Tuple[int, Any]:
2 mask = len(self.indices) - 1
3 freeslot = None
4 for index in self._generate_probes(hashvalue, mask):
5 entry_index = self.indices[index]
6 if entry_index == FREE:
7 return (index, FREE) if freeslot is None else (freeslot, DUMMY)
8 elif entry_index == DUMMY:
9 if freeslot is None:
10 freeslot = index
11 else:
12 dict_key = self.keys[entry_index]
13 if dict_key.key is key or (
14 dict_key.hashvalue == hashvalue and dict_key.key == key
15 ):
16 return (index, entry_index)
It’s quite similar to the lookup method from earlier, only this time it uses self.indices as the hash table, FREE to check for empty slots instead of None, and self.keys to check for equality and identity of keys.
__getitem__
1 def __getitem__(self, key: Any) -> Any:
2 hashvalue = hash(key)
3 _, entry_index = self._lookup(key, hashvalue)
4 if entry_index < 0: # FREE or DUMMY
5 raise KeyError(key)
6 return self.values[entry_index]
Same here! Very similar to the search method you’ve already seen, __getitem__ now uses a simple < 0 check to check if the slot is empty or dummy. If so, it returns a KeyError. If not, it returns the value from the values table.
__setitem__
1 def __setitem__(self, key: Any, value: Any):
2 self._check_keys_sharing()
3 hashvalue = hash(key)
4 indices_index, entry_index = self._lookup(key, hashvalue)
5 if entry_index < 0: # FREE or DUMMY
6 self._increase_version()
7 self.indices[indices_index] = self.used
8 dict_key = DictKey(key=key, hashvalue=hashvalue)
9 self.keys.append(dict_key)
10 self.values.append(value)
11 self.used += 1
12 if entry_index == FREE:
13 self.filled += 1 # DUMMY? `filled` would have already contained it
14 if self.filled / len(self.indices) > 2 / 3:
15 self._resize(3 * len(self))
16 else:
17 if value != self.values[entry_index]: # only if its a different value
18 self._increase_version()
19 self.values[entry_index] = v
-
Line 2 converts the dictionary to a non shared dictionary.
-
Line 6 increases the version if the slot is unoccupied.
-
Line 7 fills the hashed index in
self.indiceswith the index of the key and value which is essentiallyself.usedbecause it’s the last index ofkeysandvalues. -
Line 13 increases
self.filledIf that slot was free. That’s done because if it weren’t free, thanself.filledwould have already included it. -
Line 14 resizes the table by 3 if it’s more than 2/3 filled. It follows the logic of C Python resize.
- Line 17 checks if the new value differs from the value that is about to be replaced. The dictionary does not increase the version if nothing changes.
__delitem__
1 def __delitem__(self, key: Any):
2 self._check_keys_sharing()
3 hashvalue = hash(key)
4 indices_index, entry_index = self._lookup(key, hashvalue)
5 if entry_index < 0:
6 raise KeyError(key)
7
8 self._increase_version()
9 self.used -= 1
10 self.indices[indices_index] = DUMMY
11 # swap with the last item to avoid holes
12 if entry_index != self.used:
13 last_key_dict = self.keys[-1]
14 last_value = self.values[-1]
15 last_entry_indices_index, _ = self._lookup(
16 last_key_dict.key, last_key_dict.hashvalue
17 )
18 self.indices[last_entry_indices_index] = entry_index
19 self.keys[entry_index] = last_key_dict
20 self.values[entry_index] = last_value
21 self.keys.pop()
22 self.values.pop()
-
Line 2 converts the dictionary to a non shared dictionary.
-
Line 6 raises
KeyErrorIf the slot is unoccupied. -
Line 10 inserts a
DUMMYvalue instead of the actual value. -
Line 12: You might have thought that a
deloperation might suffice, but it would have left a hole inside thekeysandvaluestable. These tables must not contain any holes. The solution is to swap with the last item and then delete the last item. -
Line 18 changes the swapped element’s indices value to the current spot that’s being swapped.
__contains__
1 def __contains__(self, key: Any) -> bool:
2 _, entry_index = self._lookup(key, hash(key))
3 return entry_index >= 0
This method checks if the dictionary contains a certain key. It does so by checking the result of _lookup, it only contains indices below zero in the case of DUMMY or FREE.
__iter__
1 def __iter__(self):
2 return iter([dict_key.key for dict_key in self.key]s)
The dictionary’s keys list holds DictKey instances. This method creates a new list of actual the actual keys (without the wrapper class) and wraps it inside of an iterable.
Using your custom dictionary
Here’s how you can use your brand new dictionary:
d = Dictionary(
[("key1", "value1"), ("key2", "value2"), (9, "different type of key")]
)
d.show()
The show method will display all of the attributes, including the version number and the indices table.
You can use the operations you’re used to from normal dictionaries:
del d["key1"]
d["key2"] = "foo"
d.update({"key1": 10})
d.show()
In order to play with the keys sharing feature, initialize your dictionary with an already initialized dictionary:
new_d = Dictionary(d)
new_d["key1"] = "other_value" # No longer sharing keys
Note
Dictionaries Order
As a side effect of using compact dictionaries, when iterating over the dictionary, the array of indices is not needed as the elements are sequentially returned from the entries table. Since elements are added to the end of the entries each time, the dictionary automatically preserves the order of entries.
Note
Hashing Your Custom Classes
You want to use a custom class as a dictionary key, or as a value in a set. Now that you know what the hash method does, and how these structures are implemented, you know that you can take advantage of the hash method and that you must also implement __eq__ because the keys are checked for equality. Note that it is required that objects which compare equal have the same hash value. It is advised to mix together the hash values of the attributes of the object that also play a part in comparison of objects by packing them into a tuple and hashing the tuple. The following is an example of a custom class CustomClass hashing:
class CustomClass:
def __init__(self, name: str, type_: str, size: str):
self.name = name
self.type_ = type_
self.size = size
@property
def _key(self) -> Tuple[str, str, str]:
return (self.name, self.type_, self.size)
def __hash__(self) -> int:
return hash(self._key)
def __eq__(self, other) -> Boolean:
if isinstance(other, CustomClass):
return self._key == other._key
return NotImplemented
You can see that hash is being used for hashing a tuple of the custom class attributes, which should be fast enough, and that same tuple is also used for equality check.
Comprehension Check
You’ve seen the implementation of the lookup method, which contained the following line (line 63):
if dict_key.key is key or (
dict_key.hashvalue == hashvalue and dict_key.key == key
):
Notice that dict_key.key and key are both hashable objects that are being compared.
Understanding When to Use Python Hash Tables
Python hash tables (and hash tables in general) trade space for time. The need to store the key and the hash along with the value of the entries plus the empty slots, make the hash tables take up more memory - but also to be drastically faster (in most scenarios).
set vs list
Comprehension Check
- Speed: You already know that lookups are faster in sets than list - That’s the whole point of having a hash table. Iterating over a list is slighly faster than sets. Don’t take my word for it:
>>> from timeit import timeit
>>> def test_iterating(iterable):
... for i in iterable:
... pass
...
>>> setup = "from __main__ import test_iterating; iterable = set(range(10000))"
>>> timeit("test_iterating(iterable)", setup=setup, number=10000)
0.992495904000009
>>> setup = "from __main__ import test_iterating; iterable = list(range(10000))"
>>> timeit("test_iterating(iterable)", setup=setup, number=10000)
0.7114199559999861
>>> def test_lookups(iterable):
... for i in range(1000):
... if i in iterable:
... pass
...
>>> setup = "from __main__ import test_lookups; iterable = set(range(10000))"
>>> timeit("test_lookups(iterable)", setup=setup, number=10000)
0.476039572000019
>>> setup = "from __main__ import test_lookups; iterable = list(range(10000))"
>>> timeit("test_lookups(iterable)", setup=setup, number=10000)
65.991043548
- Space: If space is your main concern rather than speed, you are probably better off with lists - The difference is quite large.
>>> set1 = set(range(10000))
>>> list1 = list(range(10000))
>>> import sys
>>> set_size = sys.getsizeof(set1)
>>> list_size = sys.getsizeof(list1)
>>> set_size / list_size
>>> 6.551713800339762
-
Order: Sets are not ordered, while lists are. As we’ve talked about, sets do not implement the separate dense table that dictionaries do, which results in a single unordered table.
-
Hashing: Lists do not require their elements to be hashable as opposed to sets.
dict vs namedtuple
Unlike sets and lists, dictionaries and namedtuple are quite different in their uses. The main uses for namedtuple are when you want an unmutable object that is much more readable than a dictionary and simpler than a class. As you will soon find out, namedtuple is also much smaller than a dictionary - so add that to your considerations!
- Speed: Usually, you won’t have to deal with very large
namedtupleinstances nor will you iterate over them. I will however show the speed comparisons of the lookup function shown above, just in case you will.
>>> type_ = namedtuple("test", [f"t{i}" for i in range(1000)])
>>> t1 = type_(*list(range(1000)))
>>> d1 = {f"t{i}": 0 for i in range(1000)}
>>> setup = "from __main__ import test_lookups, t1; iterable = t1"
>>> timeit("test_lookups(iterable)", setup=setup, number=10000)
64.43791548900026
>>> setup = "from __main__ import test_lookups, d1; iterable = d1"
>>> timeit("test_lookups(iterable)", setup=setup, number=10000)
0.5148220669998409
- Space:
namedtupletakes drastically less space than a dictionary:
>>> from collections import namedtuple
>>> Car = namedtuple('Car', ['name', 'color', 'size'])
>>> car_tuple = Car(name="Toyota", color="black", size="big")
>>> car_dict = {"name": "Toyota", "color": "black", "size": "big"}
>>> import sys
>>> sys.getsizeof(car_tuple)
64
>>> sys.getsizeof(car_dict)
232
-
Order: Both are ordered (since Python 3.6).
-
Hashing:
namedtupleinstances only allow strings to be their attribute names, as opposed to dictionaries that allow everything as long as it is hashable.
Note
Conclusion
Congratulations! You’ve now had a comprehensive overview on Python hash tables. You’ve learned an important concept in computer science - hash tables, how they are implemented in Python, the awesome optimizations of Python dictionaries, and when to use Python hash tables. You now know that hash tables trade space for time, and you can even practice comparing size and speed of different data structures yourself. I hope that you feel more confident choosing data structures for your next project!
You can get all of the code you saw in this tutorial by clicking here.
Further Reading
-
Raymond Hettinger on the key ideas of Python dictionaries and how they evolved over time: https://www.youtube.com/watch?v=npw4s1QTmPg
-
Brandon Rhodes on the features and implementation of Python dictionaries: https://www.youtube.com/watch?v=66P5FMkWoVU
-
Brandon Rhodes on Python hash tables: https://www.youtube.com/watch?v=C4Kc8xzcA68
-
Laurent Luce post describing how dictionaries are implemented in the Python language: https://www.laurentluce.com/posts/python-dictionary-implementation/